Logging is an design mechanism that allow us to follow the events of the system and tracing the application for debugging purposes. A log is a sorted set of entries with an importance level and sometimes the instant of the event, the class that caused it and a description. The entries use to have one line although multi-line entries are allowed.
The most common entry levels are the following:
- ERROR: This kind of entries contains information about a important problem in the application that could cause a malfunction and should be reviewed. All runtime errors and unexpected exceptions should be logged at this level.
- WARN: At this level should be included all unexpected events that doesn't break the normal working. These messages should be attended as soon as possible.
- INFO: The information entries notifies about the start and stop of a long process or subsystem. It's usual show another meaningful messages but you shouldn't abuse to avoid the generation of a heavy log.
- DEBUG: This is a detailed information use to follow the application flow. This is only used to debug the application and these messages shouldn't be shown in a production environment.
- TRACE: A more fine coarse information about the application flow. This level could be used to notify the start and stop method for example.
In a development environment it's very common to show all levels, but in a production environment it must be limited to INFO level to avoid overloading of the system and unnecessary information. It's also possible to set a different logging level depending on package namespace.
Finally, you can push the messages on a console, a file or even a email.
Java includes a logging API in the package
java.util.logging (also called JUL) that allows you to perform a basic logging. Nevertheless, most important software project doesn't use it due to the existence of many other better libraries. Some of them are
Apache Commons Logging,
Log4j or
Logback.
With the purpose of unifying all the traces when you have several logging libraries in a project
Slf4j has been done. This work as a Facade, and this Facade include Adaptors and binding
extracted from the most popular logging libraries you can configure in
your project.
You can find many guides of how to configure an unique logging library for your project. In this article we are going to study some cases and how to find an efficient solution.
- Starting a new development with Slf4j
If you are starting a new project, the best option is to make the logging calls by the Slf4j API façade. This allows you to use the underlying framework that you prefer and change it only importing another libraries. In this page it's described how to configure your project to use the desired implementation. As you can see, the recommended implementation is Logback, because it's a native implementation of that API and it doesn't overhead the system.
Let's have a look of how to configure a Java application to log on this way:
- Prepare a new Maven project and set the pom.xml as this.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>gazpachito.examples</groupId>
<artifactId>logging</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<logback.version>1.0.13</logback.version>
</properties>
<dependencies>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
</dependencies>
</project>
This configuration will download the Logback jars and the Slf4j API.
[INFO] --- maven-dependency-plugin:2.8:tree (default-cli) @ logging ---
[INFO] gazpachito.examples:logging:jar:0.0.1-SNAPSHOT
[INFO] \- ch.qos.logback:logback-classic:jar:1.0.13:compile
[INFO] +- ch.qos.logback:logback-core:jar:1.0.13:compile
[INFO] \- org.slf4j:slf4j-api:jar:1.7.5:compile
- Copy the following code.
package gazpachito.examples.logging;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* @author jmporterog
*/
public class NewApplicationLoggingExample {
private static final Logger LOGGER = LoggerFactory.getLogger(NewApplicationLoggingExample.class);
/**
* @param args
*/
public static void main(String[] args) {
LOGGER.trace("TRACE message");
LOGGER.debug("DEBUG message");
LOGGER.warn("WARN message");
LOGGER.info("INFO message");
LOGGER.error("ERROR message");
}
}
- Run the application. The output will be the next:
19:16:54.145 [main] DEBUG g.e.l.NewApplicationLoggingExample - DEBUG message
19:16:54.148 [main] WARN g.e.l.NewApplicationLoggingExample - WARN message
19:16:54.149 [main] INFO g.e.l.NewApplicationLoggingExample - INFO message
19:16:54.149 [main] ERROR g.e.l.NewApplicationLoggingExample - ERROR message
As you can see, Logback includes a default configuration that logs the messages to the console with a debug level and the format contains the time and an abbreviated package name with the class name.
Like many others logging libraries, all those parameters are configurable by a configuration file. Logback looks for a
lookback-test.xml file in the classpath and if it's not found, try to load a
lookback.xml file. This feature is very useful if you use
Maven because you can use a different file for the testing classes.
The logger is configured as explained as following:
- The method getLogger of the LoggerFactory class returns a Logger instance. It looks for an implementation of the LoggerFactoryBinder. In the case of Logback it's included in logback-classic.jar and an adaptor isn't needed.
- When we call a method of the logger it's executed by the implementation of the Logback Logger class.
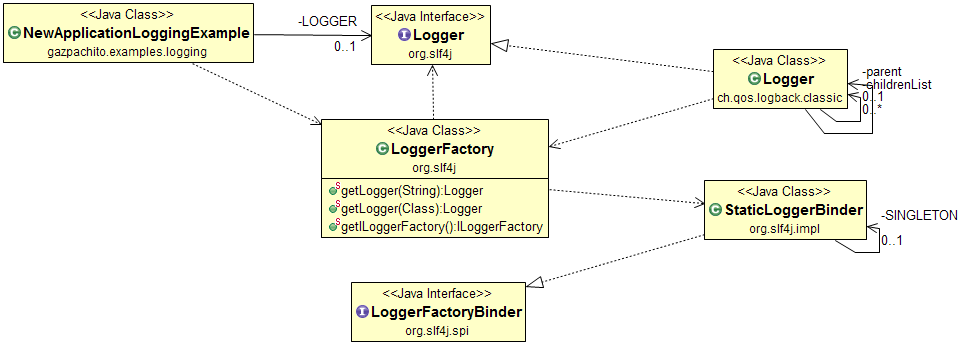 |
| Figure 1: Class diagram of the related classes in logging. |
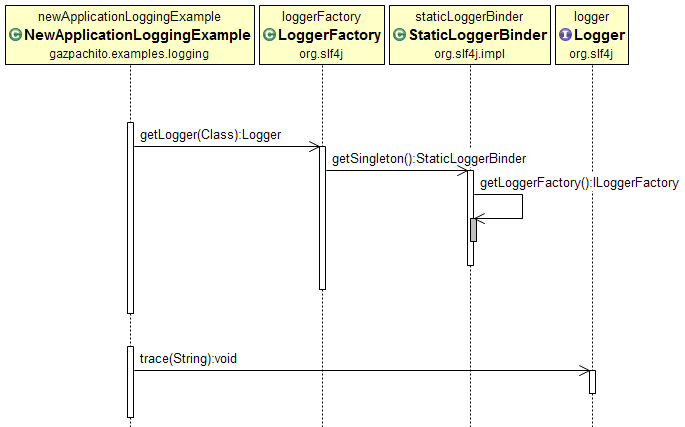 |
| Figure 2: Sequence diagram of a trace logging. |
You have a detailed information about configuring Logback in this
link. Let's have a look a sample configuration file that increases the logging level to TRACE and sends messages to an email too. First of all you need to add the
JavaMail dependency to the pom.xml file:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>gazpachito.examples</groupId>
<artifactId>logging</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<logback.version>1.0.13</logback.version>
<javax.mail.version>1.4.7</javax.mail.version>
</properties>
<dependencies>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
<dependency>
<groupId>javax.mail</groupId>
<artifactId>mail</artifactId>
<version>${javax.mail.version}</version>
</dependency>
</dependencies>
</project>
You only have to add an appender with the configuration of the sender:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<appender name="EMAIL" class="ch.qos.logback.classic.net.SMTPAppender">
<smtpHost>smtp.gmail.com</smtpHost>
<smtpPort>587</smtpPort>
<STARTTLS>true</STARTTLS>
<username>YOUR_MAIL@gmail.com</username>
<password>PASSWORD</password>
<to>DESTINY_EMAIL@DOMAIN</to>
<from>YOUR_MAIL@gmail.com</from>
<subject>Testing: %logger{20} - %m</subject>
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>%date %-5level %logger - %message%n</pattern>
</layout>
</appender>
<root level="TRACE">
<appender-ref ref="CONSOLE" />
<appender-ref ref="EMAIL" />
</root>
</configuration>
- Replace the existing logger
Many times we should trade with code that logs with many different libraries. It's a common situation when we are dealing with legacy code of our business that not uses Slf4j or we have a dependency with a library that uses it. In these cases we have to look for an Slf4j (or many ones) adapter that matches with the library calls and redirects to our infrastructure.
Let's have a look to this example. In this one, we have a legacy code that logs with Log4j and we want to replace it to Logback with Slf4j.
- pom.xml with Log4j dependency
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>gazpachito.examples</groupId>
<artifactId>logging</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<log4j.version>1.2.17</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>
</project>
In this case, Maven will only download the Log4j jar file.
[INFO] --- maven-dependency-plugin:2.8:tree (default-cli) @ logging ---
[INFO] gazpachito.examples:logging:jar:0.0.1-SNAPSHOT
[INFO] \- log4j:log4j:jar:1.2.17:compile
- Copy the following code.
package gazpachito.examples.logging;
import org.apache.log4j.Logger;
/**
* @author jmporterog
*/
public class LegacyApplicationLoggingExample {
private static final Logger LOGGER = Logger.getLogger(LegacyApplicationLoggingExample.class);
/**
* @param args
*/
public static void main(String[] args) {
LOGGER.trace("TRACE message");
LOGGER.debug("DEBUG message");
LOGGER.warn("WARN message");
LOGGER.info("INFO message");
LOGGER.error("ERROR message");
}
}
- Use the following log4j.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<appender name="console" class="org.apache.log4j.ConsoleAppender">
<param name="Target" value="System.out" />
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d{dd MMM yyyy HH:mm:ss} %5p %c{1} - %m%n" />
</layout>
</appender>
<root>
<priority value="trace" />
<appender-ref ref="console" />
</root>
</log4j:configuration>
- If you run the application it will show the following output.
26 ene 2014 21:40:39 TRACE LegacyApplicationLoggingExample - TRACE message
26 ene 2014 21:40:39 DEBUG LegacyApplicationLoggingExample - DEBUG message
26 ene 2014 21:40:39 WARN LegacyApplicationLoggingExample - WARN message
26 ene 2014 21:40:39 INFO LegacyApplicationLoggingExample - INFO message
26 ene 2014 21:40:39 ERROR LegacyApplicationLoggingExample - ERROR message
In this case, the calls to the logger are more direct. In the following diagram you can see the different calls.
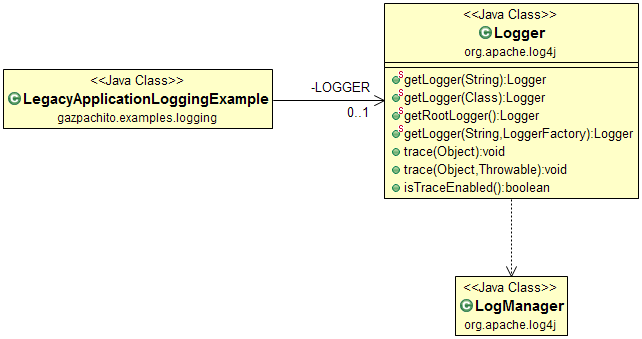 |
| Figure 3: Log4j basic class diagram. |
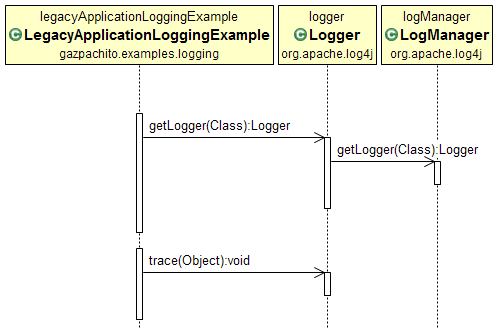 |
| Figure 4: Log4j basic sequence diagram. |
To redirect the calls of Log4j to Logback we only have to replace the
pom.xml for this one.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>gazpachito.examples</groupId>
<artifactId>logging</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<logback.version>1.0.13</logback.version>
<slf4j.version>1.7.5</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
<version>${slf4j.version}</version>
</dependency>
</dependencies>
</project>
As you can see, we have replaced the original Log4j jar and we have included log4j-over-slf4j. This includes the public classes with the same names and packages but it redirects all the calls to Slf4j and then to Logback. We can redirect the calls to another one of course and include adapters of many other logging libraries.
The result of this change can be reflected in these diagrams.
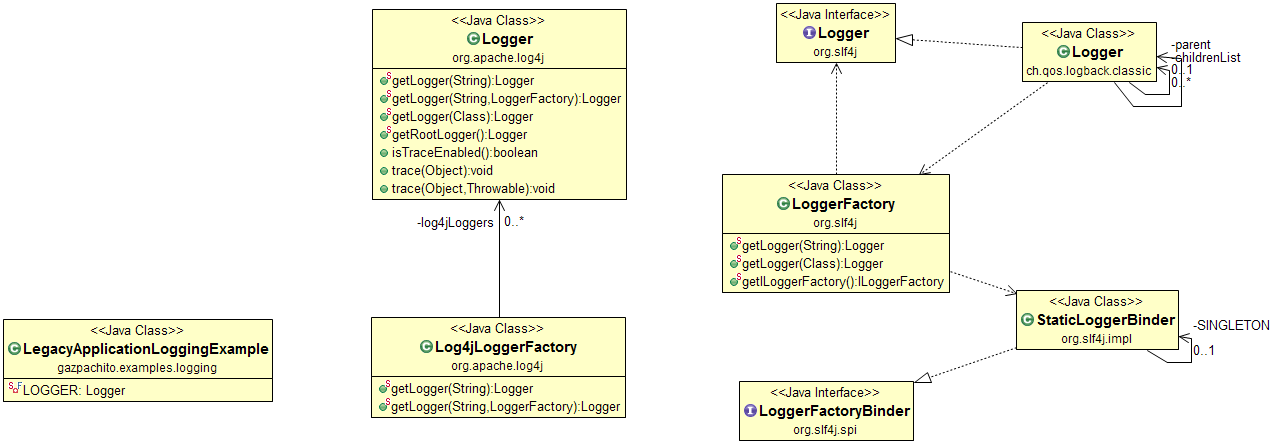 |
| Figure 5: Class diagram with the main involved entities. In this case the classes in the package org.apache.log4j.* are not the same than the Figure 3. |
 |
| Figure 6: Sequence diagram. Notice the difference with figure 4 and the new calls. |
Slf4j allows us to solve the jungle of logging frameworks in a complex software application. With a correct combination of adapters and a good configuration of the main loggers you will trace all the important messages of your application.
